Olá pessoal, tudo bem com vocês?
Hoje iremos analisar algumas ferramentas de geração de áudios através de textos. Iremos verificar diferentes formas de gerar áudios, tendo diferentes tons de voz, qualidade e ritmo.
Tópicos
- Transformação de texto para áudio
- Ferramentas que serão utilizadas
- Variações de voz
- Projeto para execução
Transformação de texto para áudio
Para realizar a transformação de texto para áudio iremos utilizar a tecnologia de TTS (Text-to-Speech), isso nos permitirá transformar quantos textos desejarmos em arquivos de áudio.
TTS (Text-to-Speech)
- Transforma texto escrito em áudio falado.
- Amplamente utilizada em assistentes virtuais, leitores de tela para pessoas com deficiência visual, e em diversas outras aplicações.
Funcionamento do TTS
- O texto é analisado para identificar palavras, frases e a estrutura gramatical. Isso inclui a identificação de números, abreviações e outros elementos que precisam ser convertidos para uma forma falada.
- A seguir, o texto é convertido em uma representação fonética, que é uma transcrição de como as palavras devem ser pronunciadas.
- A representação fonética é então convertida em áudio. Isso pode ser feito através de diferentes métodos, como concatenação de unidades de fala pré-gravadas ou síntese baseada em modelos de aprendizado profundo.
Como vamos gerar conteúdos em Português, temos modelos mais ‘limitados’ comparados a modelos em inglês.
- Modelos em inglês geralmente têm acesso a mais dados de treinamento devido à maior disponibilidade de corpora de fala em inglês. Isso pode resultar em modelos mais precisos e naturais.
Ferramentas que serão utilizadas
Iremos comparar a geração de imagens em diferentes ferramentas, utilizaremos o mesmo texto e veremos como ele é gerado em cada uma delas.
As ferramentas que serão utilizadas são as seguintes (usaremos a mensagem “Bom dia, eu sou uma ferramenta de conversão de texto em áudio” como exemplo):
Mozilla TTS
Este é um projeto de código aberto da Mozilla que visa criar um sistema de TTS de alta qualidade. Ele utiliza técnicas de aprendizado profundo para gerar fala natural e é altamente personalizável.
- Disponível em: https://github.com/mozilla/TTS
- Exemplo de áudio:
Kokoro TTS
Um modelo de ponta de texto para fala AI com parâmetros de 82M, construído na arquitetura StyleTTS 2, oferecendo síntese de voz de alta qualidade e som natural.
- Disponível em: https://kokorottsai.com/
- Exemplo de áudio:
GTTS (Google Text-to-Speech)
Este é um serviço de TTS oferecido pelo Google. Ele é amplamente utilizado devido à sua alta qualidade e suporte para múltiplos idiomas. GTTS é frequentemente utilizado em aplicações que requerem síntese de voz em tempo real.
- Disponível em: https://cloud.google.com/text-to-speech?hl=pt-BR
- Exemplo de áudio:
Coqui TTS
Este é um projeto de TTS de código aberto que surgiu como um fork do Mozilla TTS. Coqui TTS também utiliza aprendizado profundo para gerar fala natural e é projetado para ser fácil de usar e personalizar.
- Disponível em: https://huggingface.co/spaces/coqui/xtts
- Exemplo de áudio:
Variações de voz
O Kokoro TTS é uma ferramenta de síntese de voz que permite a geração de fala a partir de texto. Ele oferece diferentes variações de vozes, cada uma com características únicas.
Algumas vozes estão disponíveis:
- pf_dora: Esta é uma voz feminina. Pode ser utilizada para gerar conteúdos que requerem uma entonação mais suave ou feminina.
- pm_alex: Esta é uma voz masculina. Ideal para conteúdos que precisam de uma voz masculina, talvez com um tom mais autoritário ou formal.
- pm_santa: Outra voz masculina, que pode ter características diferentes da voz do Alex, talvez com um tom mais amigável ou descontraído.
Projeto para execução
Foi disponibilizado um projeto que permite a execução das quatro ferramentas acima. Ainda está em uma versão ‘manual’ porém em breve criarei uma versão mais simplificada e de fácil execução.
Ele está disponível em:
- https://github.com/marcelo3macedo/collection-tools-tts
No qual permite através de requisições, informando o que é desejado você receba o arquivo de voz já realizando a transcrição do conteúdo. Conforme abaixo:
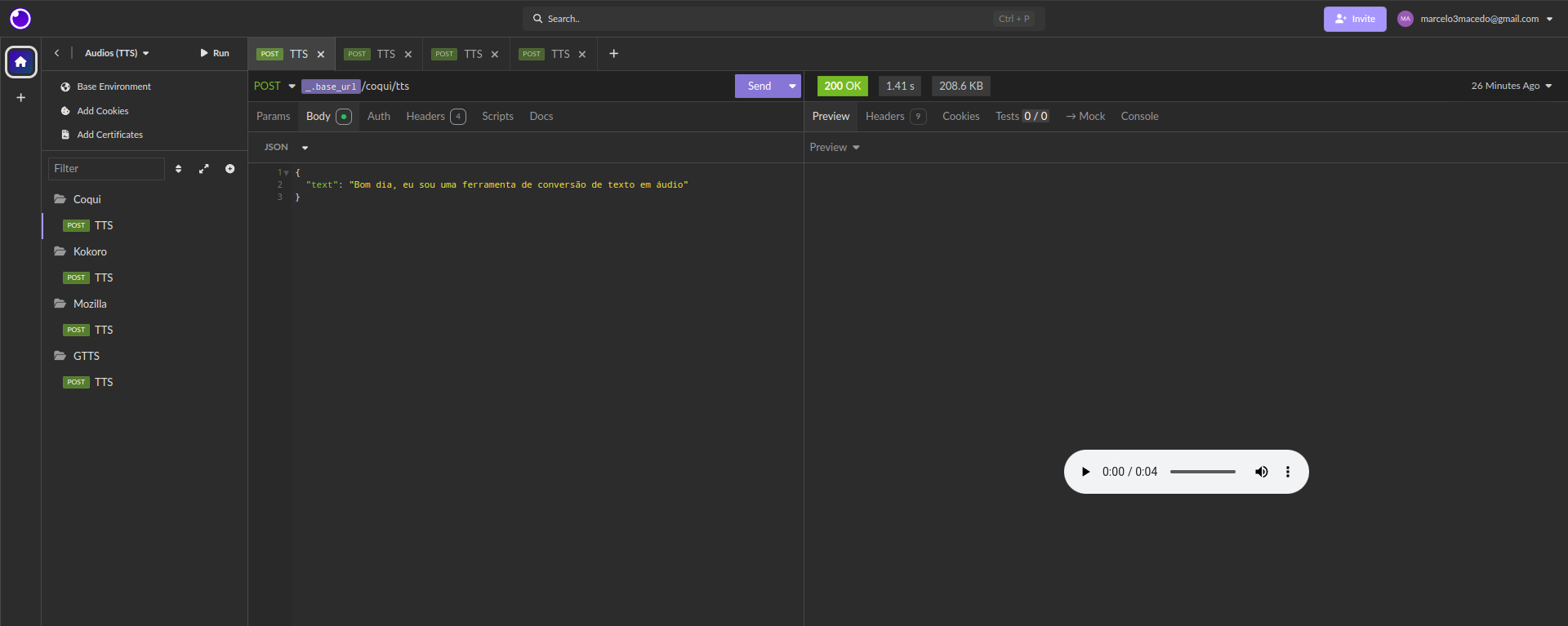
Na próxima postagem irei integrar essa ferramenta com o N8N. Iremos criar um processo de automação no qual através de inteligência artificial e telegram iremos enviar diariamente para a pessoa um trecho da bíblia ou de um livro no qual ela está lendo.
O objetivo é tornar simples e criar o hábito na pessoa de diariamente em um horário selecionado receber e ouvir algo que agregará ao seu dia.
E por hoje é só pessoal,
Até a proxima.