Olá, tudo bem?
Nesse post iremos transformar textos em arquivos de áudio, iremos utilizar uma tecnologia disponibilizada pela Microsoft chamada Edge TTS.
Para isso, utilizaremos um fluxo N8N que receberá a voz escolhida e o texto desejado, com essas informações o fluxo irá criar o áudio desejado pelo usuário.
Tópicos:
- Ferramenta de transformação texto para áudio
- Acessando a API e gerando um áudio
- Gerenciando a criação de áudios com uma planilha
Ferramenta de transformação texto para áudio
Utilizaremos uma API para realizar o trabalho de transformação de texto para áudio, nesse caso utilizaremos o edge_tts.
O edge_tts é uma biblioteca Python que utiliza a API de texto para fala da Microsoft Edge para converter texto em fala.
Algumas características do edge_tts incluem:
- Suporte a múltiplos idiomas e vozes: A API oferece uma variedade de vozes e idiomas, permitindo que os usuários escolham a voz que melhor se adapta às suas necessidades.
- Facilidade de uso: A biblioteca é projetada para ser fácil de integrar e usar em projetos Python, com uma interface simples para converter texto em áudio.
- Qualidade de áudio: A tecnologia de texto para fala da Microsoft é conhecida por sua alta qualidade de áudio, proporcionando uma experiência de audição natural e clara.
- Personalização: Algumas versões da API permitem ajustes na velocidade, tom e volume da fala, oferecendo maior controle sobre a saída de áudio.
Disponibilizamos uma API no qual terá a funcionalidade de gerar os áudios com o edge_tts utilizando a tecnologia python.
Caso você possua Docker instalado na sua máquina, você poderá rodar a API através do comando:
docker run -p 5000:5000 marcelo3macedo/blogs_generate_ttsIsso disponibilizará a API na porta 5000, ou http://localhost:5000
Acessando a API e gerando um áudio
Disponibilizamos um fluxo que recebendo as variáveis “prompt” (texto a ser gerado) e “voice” (tom de voz a ser utilizado) ele irá transformar o texto em áudio.
Esse fluxo poderá ser chamado por outros fluxos, tornando o uso mais simples.
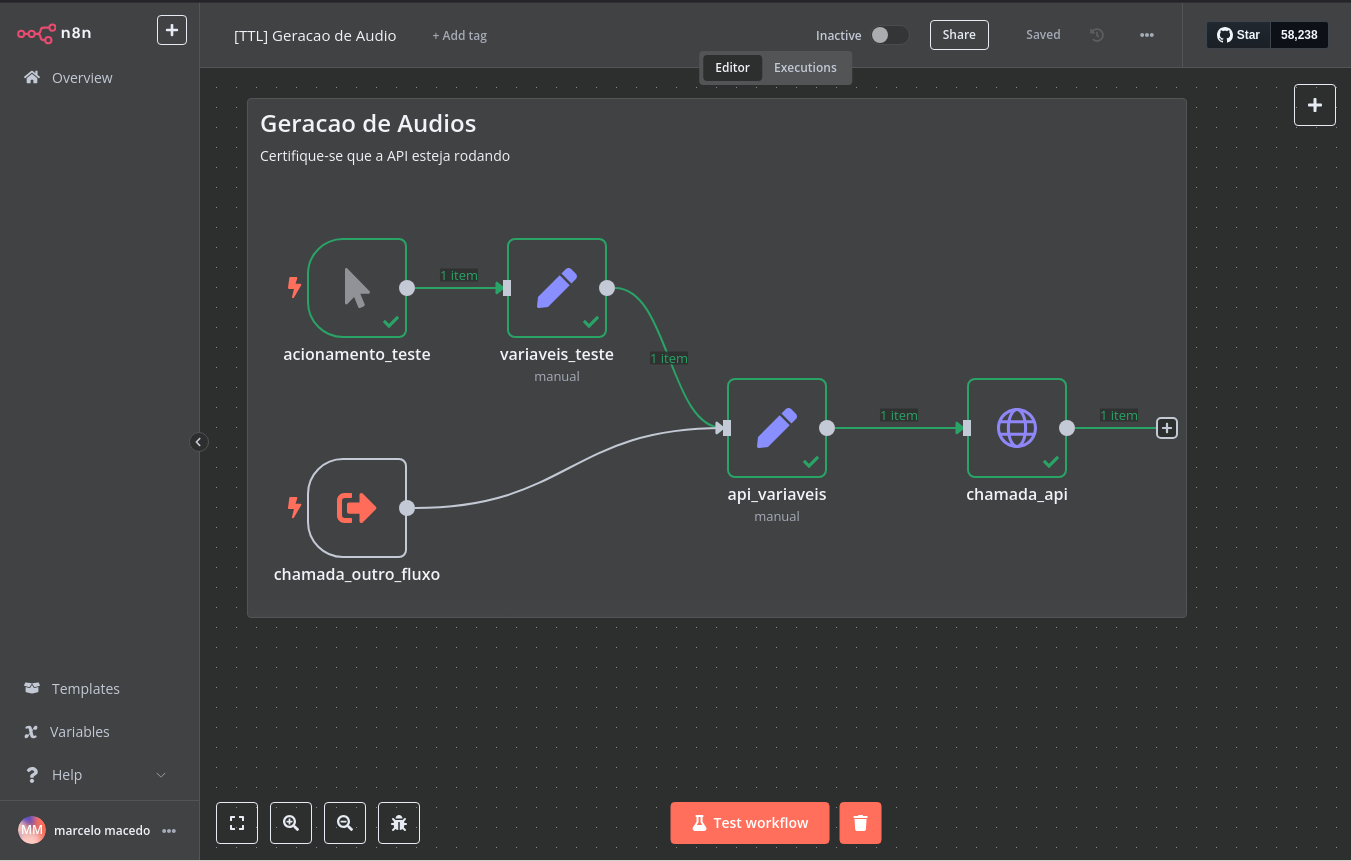
Nele temos a seguinte estrutura:
Porta de Entrada:
- Acionamento Teste: pode ser utilizado para verificar o funcionamento do fluxo clicando em “Test Workflow”, ele executará a criação do áudio utilizando um texto e uma voz de exemplo.
- chamada_outro_fluxo: permite que outro fluxo envie as variáveis necessárias e obtenha como retorno um áudio gerado pela API.
variaveis_fixas: - Aqui temos o endpoint (ou seja, o local aonde está a nossa API), caso tenha executado em outra porta ou utilizará a API hospedada em algum local, mude a variável “endpoint”.
Chamada API: - Realiza a comunicação com a API para a geração do áudio utilizando as variáveis recebidas.
Esse fluxo está disponível para download aqui:
Exemplo de áudios gerados
Voz de duarte:
Voz de raquel:
Voz de antonio:
E por isso é só, espero que tenha gostado.
Até mais.